Architecture
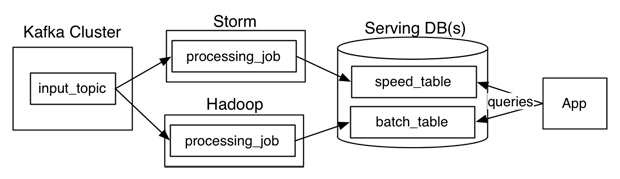
Immutable sequence of records is captured and fed into a batch system and a stream system in parallel. Transformation logic is made twice on both of these system, you combine together the results from both of them at query time to produce a complete answer. Or people often use two different databases to store the output tables, one optimized for real time and the other optimized for batch updates.
Good for apps built around complex async transformations that need to run in low latency. E.g. a news recommendation system
Advantages
- Modeling data transformation as a series of materialized stages, bc the MapReduce workflow is tractable
- Reprocessing outputs when code changes (needs to evolve to handle more fields etc.)
processing input data over again to re-derive output. Code will always change. So, if you have code that derives output data from an input stream, whenever the code changes, you will need to recompute your output to see the effect of the change.
- (Some not strong ones according to the O’Reily article) that it beats CAP-theorem - this is an architecture for asynchronous processing, so the results being computed are not kept immediately consistent with the incoming data; real-time processing is less approximate than batch processing (It is true that the existing set of stream processing frameworks are less mature than MapReduce, but there is no reason that a stream processing system can’t give as strong a semantic guarantee as a batch system.)
Disadvantages
- Maintaining code in two places for handling the stream and batch processing systems.
Even if there are frameworks like SummingBird which compiles down to support both types of systems,the operational burden of running and debugging two systems is going to be very high. Any new abstraction can only provide the features supported by the intersection of the two systems. Worse, committing to this new uber-framework walls off the rich ecosystem of tools and languages that makes Hadoop so powerful (Hive, Pig, Crunch, Cascading, Oozie, etc).
TIP
Use a batch processing framework like MapReduce if you aren’t latency sensitive, and use a stream processing framework if you are, but not to try to do both at the same time unless you absolutely must.